머신러닝(Machine Learning)
ML, Supervised Learning, Unsupervised Learning, Reinforcement Learning
안녕하세요. 데이터 사이언티스트를 위한 정보를 공유하고 있습니다.
M1 Macbook Air를 사용하고 있으며, 블로그의 모든 글은 Mac을 기준으로 작성된 점 참고해주세요.
머신러닝이란?
인공지능, 머신러닝, 딥러닝은 누구나 한 번쯤 들어봤을 정도로 요즘 굉장히 핫한 키워드이며
서로가 상하위 개념으로 관련이 있습니다.
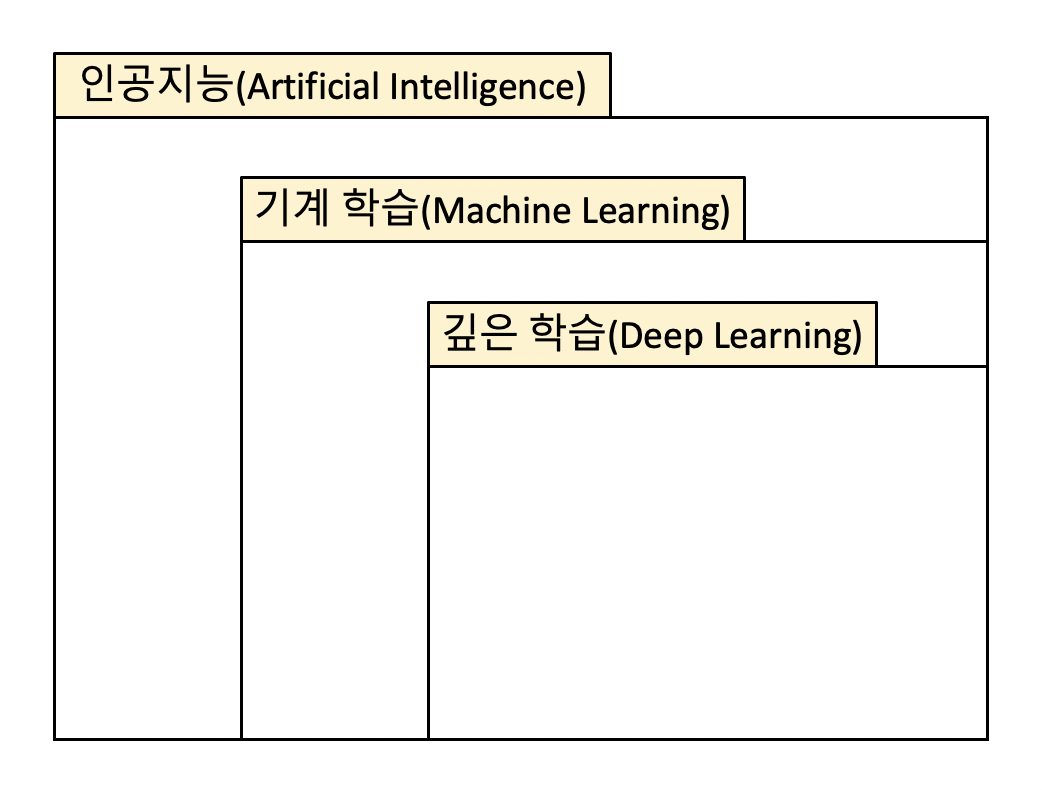
인공지능은 인간의 지능을 모방하고 구현하려는 컴퓨터 사이언스의 분야 중 하나이고,
머신러닝은 인공지능의 하위 개념으로서 인공지능의 여러 분야 중 하나입니다.
기존 프로그래밍의 알고리즘은 사람이 직접 필요한 규칙을 컴퓨터에 입력하는 방식이었다면,
머신러닝 알고리즘은 데이터를 기반으로 데이터의 피처(변수) 간 패턴 및 상관관계를 컴퓨터가 스스로 학습하게 하는 방식으로 진행됩니다.
또한 딥러닝의 경우에는 다시 머신러닝의 하위 개념으로서 머신러닝 기법 중 하나입니다.
머신러닝의 종류
머신러닝 알고리즘은 주어지는 데이터 혹은 방식에 따라 크게
지도 학습(Superviesed Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)
세 가지의 종류로 분류할 수 있습니다.
1. 지도 학습
지도 학습과 비지도 학습에서 말하는 ‘지도’는 기계(컴퓨터)에게 정답을 지도해주느냐를 의미합니다.
따라서 지도 학습은 데이터에 정답 정보(label)가 존재하여
컴퓨터에게 정답을 알려주면서 패턴을 학습하도록 하는 방식입니다.
분류(Classification)나 회귀(Regression) 알고리즘이 지도 학습에 해당합니다.
예를 들어 스팸 메일 관련 데이터가 있다면
각 데이터마다 스팸인지 스팸이 아닌지에 대한 정답 정보가 주어지고,
컴퓨터가 스팸 메일에 대한 패턴을 학습하여 스팸의 여부를 예측하는 것이 분류이고,
또 예를 들어 집의 크기, 방의 개수, 학교와의 거리 등의 피처를 포함하는 부동산 관련 데이터가 있다면
각 데이터에 대해 집값이라는 정답이 주어지고,
컴퓨터가 여러 피처에 대한 패턴을 학습하여 집값이 얼마일지 예측하는 것이 회귀입니다.
분류는 정답 정보가 이산적인 반면 회귀는 정답 정보가 연속적입니다.
2. 비지도 학습
비지도 학습은 데이터에 대한 정답 정보가 존재하지 않거나 구조를 알 수 없는 상태에서 의미 있는 정보를 추출하는 방식입니다.
군집화(클러스터링)나 차원 축소 분야가 비지도 학습에 해당합니다.
군집화는 사전 정보가 없는 데이터에서 의미 있는 클러스터(군집)로 조직하는 기법입니다.
예를 들어 마케터가 고객을 관심사에 따라 각각 군집화하고 이에 맞는 마케팅 전략을 세울 수 있습니다.
차원 축소는 전처리 단계에서 종종 사용되는 기법입니다.
데이터의 피처가 많을수록 차원이 커지게 됩니다.
또한 그러한 고차원 데이터를 다루게 되는 경우가 일반적이기도 합니다.
하지만 차원이 커지면 데이터가 서로 멀어지고 밀도는 떨어지게 되는데 이를 sparse하다고 표현합니다.
이러한 데이터가 sparse한 상황에서는 저장 공간이나 모델의 성능에 문제가 발생할 수 있습니다.
이때 데이터의 정보를 최대한 유지하며 더 작은 차원을 가진 subspace로 데이터를 압축하는 것이 바로 차원 축소입니다.
3. 강화 학습
강화 학습은 환경과 상호 작용하여 에이전트의 성능을 향상하는 방식인데
이에 대한 상세한 설명 보다는 이번 포스팅에서는 직관적인 이해를 돕기 위해 가볍고 쉽게 말씀드리곘습니다.
지도 학습에서 컴퓨터에게 피처에 대한 정답을 알려주듯이,
강화 학습에서는 특정 행동에 대하여 보상 함수를 통해 행동이 얼마나 좋았는지 알려줍니다.
즉 가장 좋은 행동(선택)일 경우 보상을 최대화하고, 벌을 최소화하는 방식으로 학습합니다.
행동심리학에서 영감을 받아 만든 머신러닝 알고리즘이라고 하는데요.
예를 들어 좋은 행동을 칭찬하고 나쁜 행동을 벌하며 어린 아이를 훈육하는 방식이 강화 학습의 개념과 비슷하다고 볼 수 있겠습니다.
알파고와 같이 게임에서 최적의 수(선택)를 찾는 데 자주 사용됩니다(알파고는 지도 학습도 사용됨).
읽어주셔서 감사합니다.
정보 공유의 목적으로 만들어진 블로그입니다.
미흡한 점은 언제든 댓글로 지적해주시면 감사하겠습니다.
댓글남기기