데이터 인코딩(Data Encoding) 1
One-Hot encoding, Label encoding
안녕하세요. 데이터 사이언티스트를 위한 정보를 공유하고 있습니다.
M1 Macbook Air를 사용하고 있으며, 블로그의 모든 글은 Mac을 기준으로 작성된 점 참고해주세요.
데이터 인코딩(Encoding)
사이킷런의 머신러닝에서 데이터의 입력 값은 숫자만 인식합니다.
따라서 문자열의 경우 숫자 형으로 바꾸어 주는 인코딩 작업이 필요합니다.
대표적인 세 가지의 인코딩 방식이 있습니다.
- Label encoding
- One-Hot encoding
- Mean encoding
Mean encoding은 내용이 상대적으로 많기 때문에 다음 포스팅에서 다루기로 하고,
이번 글에서는 Label encoding과 One-Hot encoding에 대해 설명해 보도록 하겠습니다.
1. Label encoding
Label encoding은 카테고리 피처를 숫자형으로 변환하는 것입니다.
예시를 통해 보여드리겠습니다.
In:
from sklearn.preprocessing import LabelEncoder
# 사이킷런에서 전처리를 도와주는 preprocessing 모듈로 부터 가져옴
fruits = ["사과", "딸기", "바나나", "사과", "수박", "청포도", "딸기", "청포도", "딸기"]
# 임의의 카테고리 피처를 만듦
encoder = LabelEncoder()
# LabelEncoder()의 객체 생성
encoder.fit(fruits)
# 여기서 fit은 학습의 의미 보다는 원하는 형태로 변환하기 위해 구조를 맞춘다는 의미
labels = encoder.transform(fruits)
# 구조를 맞춘 후 encoder로 fruits의 문자열을 숫자형으로 변환
labels
Out:
array([2, 0, 1, 2, 3, 4, 0, 4, 0])
임의로 과일명으로 카테고리 피처를 만들었는데요.
LabelEncoder()를 encoder라는 이름의 객체로 생성하고,
인코딩 이전에 인코딩을 위한 데이터의 구조를 맞추기 위해 fit()을,
최종적으로 변환을 위해 transform()을 호출하면
fruit의 과일명들이 숫자형으로 바뀌어 반환되는 것을 확인할 수 있습니다.
여기서 fit()과 transform()을 나누어 사용했는데 fit_tansform()을 호출하여 한 번에 진행하셔도 됩니다.
위의 예시처럼 데이터가 작은 경우에는 인코딩이 어떻게 진행되었는지,
즉 어떤 과일이 어떤 숫자로 바뀌었는지 쉽게 확인할 수 있습니다.
하지만 데이터가 커지면 이를 쉽게 확인하기 어려운데요.
이때 classes 속성값으로 확인하면 됩니다.
In:
encoder.classes_
# 어떤 문자열이 어떤 숫자로 변환되었는지 확인
Out:
array(['딸기', '바나나', '사과', '수박', '청포도'], dtype='<U3')
반환되는 배열의 순서대로 숫자가 변환된 것입니다.
이러한 Label encoding의 문제점이 있는데요.
카테고리 별로 숫자가 부여되는데 특정 머신러닝 알고리즘에서는 숫자의 크기에 따라 가중치가 부여되기도 한다는 점입니다.
위의 예시로 설명을 하자면,
일부 머신러닝 알고리즘이 4로 변환된 ‘청포도’라는 과일의 중요도를 상대적으로 더 크게 인식할 수 있다는 것입니다.
선형 회귀(Linear Regressioin)와 같은 머신러닝 알고리즘에는 적절하지 않은 인코딩 방식이고,
숫자의 크기에 대한 의미를 반영하지 않는 트리 구조 기반 머신러닝 알고리즘에서는 Label encoding을 사용하여도 문제가 없습니다.
2. One-Hot encoding
앞서 말씀드린 Label encoding의 문제점을 해결하기 위한 인코딩 방식이 바로 One-Hot encoding입니다.
One-Hot encoding은 인코딩하려는 카테고리 피처 값의 모든 종류를 칼럼으로 생성하고,
피처 값이 해당하는 칼럼에만 1, 나머지 칼럼에는 0을 표시하는 인코딩 방식입니다.
글로는 이해가 어려울 수 있는데 다음 그림을 보시면 바로 이해가 되실 거에요.
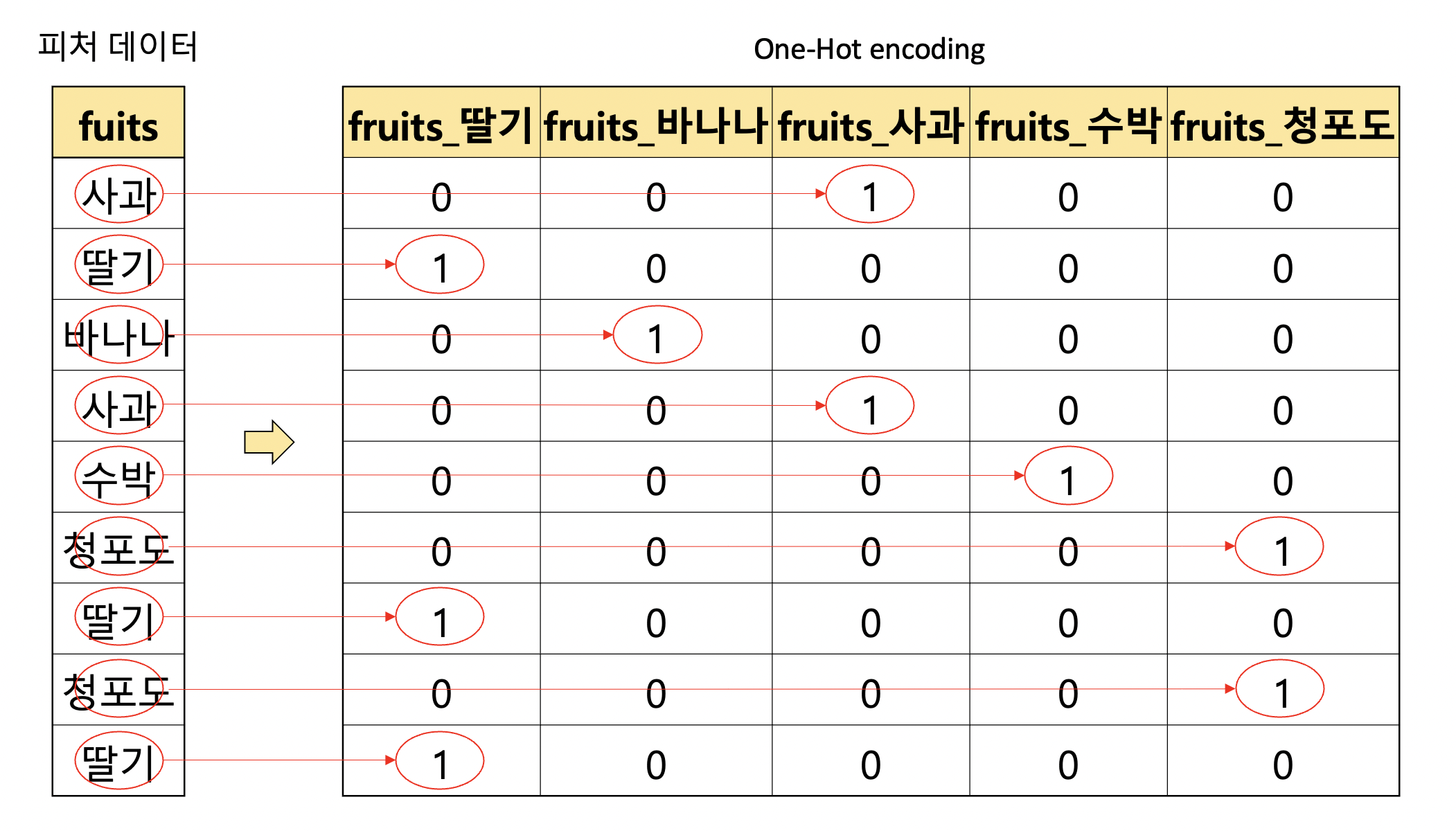
모든 과일 종류가 칼럼으로 만들어지고,
피처 데이터에 해당하는 칼럼에만 1이 입력되어 있는 것을 확인할 수 있습니다.
코드로도 바로 확인해 볼 텐데요.
사이킷런의 preprocessing 모듈에는 OneHotEncoder()가 있습니다.
하지만 이를 활용하기 전에 먼저 Label encoding을 통해 숫자로 변환시키고, 또 2차원의 데이터로 변환해줘야 하는 번거로움이 있습니다.
그래서 저는 One-Hot encoding을 훨씬 편리하게 적용할 수 있는 판다스의 API, get_dummies()를 사용하고자 합니다.
In:
import pandas as pd
fruits = {"fruits": ["사과", "딸기", "바나나", "사과", "수박", "청포도", "딸기", "청포도", "딸기"]}
# Label encoder에서 사용한 임의의 카테고리 피처
fruits_df = pd.DataFrame(fruits)
# fruits를 데이터 프레임 형식으로 저장
encoded_fruits = pd.get_dummies(fruits_df)
# One-Hot encoding
one_hot_encoding_fruits = pd.concat([fruits_df, encoded_fruits], axis = 1)
# 원본 데이터와 One-Hot encoding을 적용한 후의 데이터를 병합
one_hot_encoding_fruits.set_index("fruits")
# 위의 그림처럼 보이기 위해 index를 fruits 칼럼(원본 데이터)으로 지정
Out:
| fruits_딸기 | fruits_바나나 | fruits_사과 | fruits_수박 | fruits_청포도 | |
|---|---|---|---|---|---|
| fruits | |||||
| 사과 | 0 | 0 | 1 | 0 | 0 |
| 딸기 | 1 | 0 | 0 | 0 | 0 |
| 바나나 | 0 | 1 | 0 | 0 | 0 |
| 사과 | 0 | 0 | 1 | 0 | 0 |
| 수박 | 0 | 0 | 0 | 1 | 0 |
| 청포도 | 0 | 0 | 0 | 0 | 1 |
| 딸기 | 1 | 0 | 0 | 0 | 0 |
| 청포도 | 0 | 0 | 0 | 0 | 1 |
| 딸기 | 1 | 0 | 0 | 0 | 0 |
One-Hot encoding에도 문제점이 존재합니다.
피처 내에 카테고리의 종류가 많은 경우(high cardinality)에 칼럼을 많이 생성하게 되고,
이는 모델의 학습 시간을 길게 만듭니다.
또한 Random Forest 모델의 경우에는 일부 피처만 사용하여 트리를 만드는데
다른 피처보다 One-Hot encoding으로 생성된 피처들이 더 많이 사용될 수도 있다는 문제점이 있습니다.
읽어주셔서 감사합니다.
정보 공유의 목적으로 만들어진 블로그입니다.
미흡한 점은 언제든 댓글로 지적해주시면 감사하겠습니다.
댓글남기기